
一 . Nvidia Tesla V100 基本參數
| 第二代的NVLinke高速互聯技術實現更高的頻寬,更多的連接與改善多GPU之間與多GPU及CPU之間系統配置更多的延展性。GV100以每條25 GB / s的速度支持最多6條NVLink連接,總共300 GB / s。
|
 |


二 . 關於Volta架構
A . Tensor Cores
在Nvidia GPU最新一代的volta架構上一個重要的特性就是它的Tensor Cores,Tensor Cores 是專門針對深度學習所設計的。
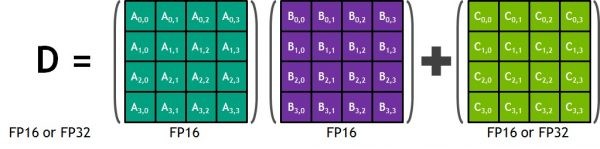
每個Tensor Cores 為一個4x4x4的矩陣處理陣列原件,同時執行一個D = A * B + C的矩陣運算。如上圖所示A , B, C, 和 D 皆為4x4的矩陣,以半精度計算(FP16)運行4X4(A&B)矩陣相乘而結果在與4x4(C矩陣)相加且C和D矩陣可為單精度或半精度運算。
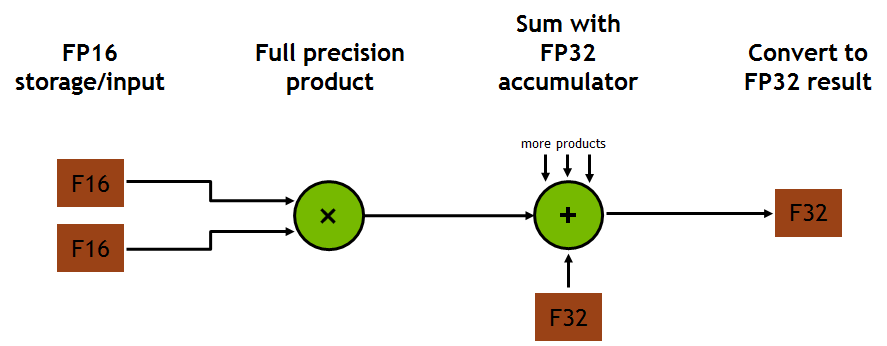
這意味著在每個時脈週期裏一個Tensor Cores可執行128次浮點FMA混合精度運算(mixed-precision operations) ,也就是矩陣(FP16)相乘產生full-precision product且在運行矩陣相加(FP32) ,如上圖。且一個SM(streaming multiprocessor)含有8個Tensor Cores因此每個時脈週期裏可執行1024 次浮點運算,這比常規的CUDA Core單精度運算還要快8倍。所以深度學習若要在這個硬體上受益,在深度學習框架上模組應該以混合精度運算(半精度及單精度)或是單純半精度運算來編寫達到高效的使用Tensor Cores。
B . Volta SM

以Nvidia Tesla V100為例,採用Volta GV100 GPU 這是當今最高效能的平行運算處理器,GV100在硬體設計上具有重大的創新這為深度學習算法和框架提供了大量的加速也為HPC系統和應用提供更多的計算能力。
與上一代Pascal GP100 GPU一樣,GV100 GPU由多個GPU組成包含GPC(Graphics Processing Cluster),TPC (Texture Processing Cluster),SM(streaming multiprocessor),和記憶體控制器。完整的GV100 GPU包括:
6個GPCs
每個 GPC 包括 :
- 7個TPCs (each including two SMs)
- 14個 SMs
84個 Volta SMs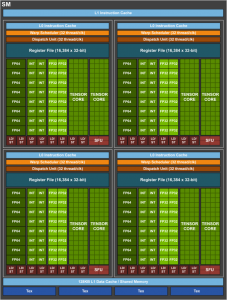
每個SM 包括 :
- 64個 FP32 cores
- 64 個INT32 cores
- 32個 FP64 cores
- 8 個Tensor Cores
- 4個texture units
8個 512-bit memory controllers (共4096 bits)
一個完整的GV100 GPU總共有5376個FP32 Cores,5376個INT32 Cores,2688個FP64 Cores,672個Tensor Cores和336個texture units。
Volta SM 更新重點 :
- 專為深度學習矩陣運算而設計的新型混合精度FP16 / FP32 Tensor Core。
- 增強L1 資料快取使其提供更高的效能及更低延遲。
- 為了更快速的解碼而優化指令集以及減少指令集延遲。
- 更高的時脈及更高的供電效率。